WebRTC P2P を使った画面共有サービスを作ってみた
三行まとめ
- WebRTC の getDisplayMedia API を利用した P2P で画面共有するサービスを作りました。
- 全て Managed Service (AWS & Firebase) 上で動作しており、ほぼノーメンテナンスでそれなりスケールします。
- 無料。ただし、音声無し、TURNサーバー無し、SLA 無しで、繋がらないこともそれなりにあると思うので、クリティカルな用途に使用することは非推奨
使い方
どういう風に使うのか、また遅延はどれくらいなのかを以下の動画をご覧ください。 配信側は WiFi で、視聴側の iPhone は LTE 回線で繋がっています。
Fully managed and serverless Screen Sharing Service: getdisplay.media
- 配信は GitHub 認証が必須ですが、視聴側はシェアされた URL を開くだけで認証不要です。
- 配信できるのは Chrome M72以上, FireFox 66以上, Chromium ベースなEdge のみ。
- 視聴側は WebRTC Unified Plan をサポートしていればいいので、上記のブラウザに加えて、macOS 10.14.4 または iOS 12.2 以降の Safari でも見えます。(macOS 10.14.4 / iOS 12.2 の方は「実験的な機能」から WebRTC Unified Plan を有効化してください。macOS 10.14.5 / iOS 12.3 からはデフォルトで有効化されいます。)Android は手元に端末がなかったので未確認ですが、Chrome M72 以降を使えば見えるはずです。
使っている技術
- Frontend
- React (可能な限り、Hooks を利用)
- AWS S3 にデプロイして、CloudFront 経由で配信
- 認証
- Signaling Server
- Serverless WebRTC Signaling Server の Firebase Authentication 対応カスタマイズ版
- AWS のマネージドサービス上で動作 (API Gateway, Lambda, DynamoDB)
ソースコードの公開の予定はありませんが、特に秘密があるわけではないので興味があって話を聞きたいという人がいれば、Twitter でお声がけください。
Kazuyuki Honda (@hakobera) | Twitter
過去(7年前)には WebSocket で画面を PNG として転送するという力技をやっていましたが、WebRTC ですごく簡単にできるようになったので、ブラウザの進歩を感じました。
最後に
WebRTC はがっつりやろうと思うと大変難しいですが、JavaScript の API を叩いてブラウザ上で動かすだけなら簡単です。 動画、音声とか、話題のゲームストリーミングなどに興味のある人は触ってみるといいのではないでしょうか。
より詳細を知りたくなった場合は、WebRTC SFU を開発している時雨堂さんに資料がまとまっていて大変参考になります。
海外カンファレンスの CFP の書き方 - RubyConf Taiwan 2016 の事例
この記事は Recruit Engineers Advent Calendar 2016 の15日目の記事です。
12月2〜3日に開催された RubyConf Taiwan 2016 にスピーカーとして参加してきました。
この記事ではカンファレンスそのものではなく、その前段階の CFP の書き方について、実際に RubyConf Taiwan 2016 に提出した私の実例をあげて、CFP に書く内容と、どういう点に注意して書いたかというのを解説してみたいと思います。自分自身も初めての CFP かつ、英語の CFP だったので、同じように挑戦してみたい人の参考になれば良いな、と思います。
なお、カンファレンスの雰囲気自体は4日目担当の remore さんが書いていますので、ぜひご覧ください。初めての海外カンファレンスでしたが、発表もパーティーもセッションもすごく面白かったです。
RubyConf Taiwanが良い感じだった | 48JIGEN *Reloaded*
実際に提出した CFP
私が実際に RubyConf Taiwan 2016 に提出した CFP の内容と解説を以下に書いていきます。 英語の原文、そして日本語の解説という体裁で書きます。そして、進化した Google 翻訳には大変お世話になったこと、ここでお礼を申し上げておきます。
Bio (自己紹介)
Kazuyuki loves Ruby and a cup of coffee. After working 9 years at IBM, M3 as a Java/Node.js web application developer, he joined EdTech company Quipper as a DevOps engineer. And now working on to make something automatic.
自己紹介なので、自由に書けばいいと思います。実際、ちゃんと経歴を書く人もいれば、Ruby Lover とか一言で済ませている人もいます。注意するとすれば、カンファレンスの雰囲気に合わせる、ということです。ビジネスよりのカンファレンスの場合は、経歴を書いておくのが無難かと思います。
Title
How to write complex data pipeline in Ruby
セッションのタイトルです。タイトルは審査する側が最初にふるいにかけるものだと思うので、内容が分かりやすく、かつ簡潔に書くように心がけました。
個人的には Data Pipeline ではなく、Workflow と書きたかったのですが、データを処理する Workflow なのか、申請の承認フローなどの Workflow とどちらの意味にとらえられるか怪しいなと思い、Data Pipeline という単語を選びました。
Abstract (概要。大体の場合、これが公式サイトに掲載されます)
We often write a code to build data pipelines, which include multiple ETL process, summarize large size data, generate reports and so on. But it's not easy to write robust data pipelines in Ruby. Because there are many things to consider not only write a business logic but idempotence, dependency resolution, parallel execution, error handling and retry.
I'm working on it over 2 years, so I want to share how to write complex data pipelines in Ruby using tumugi, which is a gem I made.
タイトルと同じくらい重要なのが、この概要です。公式サイトに掲載される関係で、文字数制限があることがあります。ですので、できるだけ簡潔に重要な点だけを書くことを心がけました。今回は自作の gem の話をするのと、Markdown が許可されていたので、公式サイトへのリンクなどを張って、興味を持ってくれた審査員がより詳細な情報を得やすいようにする点、工夫してみました。
Outlines
I'm plan to talking about written in http://tumugi.github.io/architecture/ with more detail and samples.
- What is data pipeline?
- Why is writing data pipe line so difficult?
- Idempotence
- Dependency resolution
- Parallel execution
- Error handling
- Retry
- How to resolve?
- Basics of tumugi (Task, Target, Parameter and Plugin)
- Rake-like internal DSL
- Plugin architecture
- Show concrete examples (https://github.com/tumugi/tumugi-recipes)
- Simple ETL
- Integrate with Google Cloud Services
- Multiple ETL with Embulk and Google BigQuery
- Write your own plugin
For more detail about tumugi, see followings.
Official Page: http://tumugi.github.io/ Github: https://github.com/tumugi
Intended audience is DevOps/Data engineer or any engineer who are interested in data analytics.
これは公式サイトには掲載されていないもので、概要に書ききれなかった詳細や、対象としている聴講者などについて書きます。 審査をする運営の人にしか見えない情報なので、ネタバレを覚悟で、結構細かいところまで書いてみました。既に GitHub や個人のブログなどで関連する情報を書いていれば、そのページへのリンクを適切に張っておくことで、ここに書いた文章を補強や裏付けすることができると思います。なお、ここで目次レベルまで詳細を書いておいたので、後でスライドを作る時に悩まなくて済むという副次的効果がありましたので、頭の整理としても目次を書くというのはお勧めです。
あと、「対象としている聴講者」は結構重要だと思っていて、これがカンファレンスの参加者の層と合っていないと採択されにくいでしょう。これを書いてみて、なんかカンファレンスの雰囲気とあっていないなと感じたら、そもそも応募するカンファレンスの選択を間違っていないか、もう一度検討してみましょう。
Pitch
There are some famous date pipeline library, such as Luigi and AirFlow, but it's written by Python, not Ruby! We can use python but I'm a Ruby lover, I believe people, who build their applications in Ruby, want to write it in Ruby. Because some code can share, especially database model.
So I want to share knowledge how to write data pipelines in Ruby. My knowledge is summarized in tumugi which is ruby port of Luigi, but more simple and provide rake like DSL and plugin mechanism.
I'm happy if someone learn about data pipelines in Ruby, and write their own data pipe line or tumugi plugin.
これも公式サイトには掲載されていないもので、発表にかける意気込みを書きます。具体的にどの程度審査に影響するかはわからないのですが、審査員の立場に立って考えると、ここまでの情報で当落線上に並んだセッションの合否をここの「熱さ」で決めているのではないかと思います。
なので、発表にかける熱い思いを書いておきましょう。今回は RubyConf Taiwan だったので、Ruby への思いを綴りました。
実際の発表内容
スライドはこちら。
発表内容の動画は例年通りなら、数ヶ月以内には公式サイトにアップロードされるはずです。 実際にどういう風に英語で発表したのか知りたい方は、公式サイトをチェックしてみてください。
まとめ
RubyConf Taiwan 2016 にスピーカーとして採択されたセッションの CFP の実例を掲載し、その解説しました。
個人的に日本のエンジニアのレベルは高く、海外カンファレンスでもガンガン発表して行けると思っています。 まずは気軽に CFP に提出してみてはどうでしょうか。この記事が、その一助になれば幸いです。
スタディサプリ on Quipper プラットフォームを支える技術
前置き
この記事を公開した当時はまだオープンにできなかったのですが、実はこの記事は2月25日にリリースされたスタディサプリ(受験サプリ)を Quipper のプラットフォームに載せ替えるという移行プロジェクトを前提として内容も含んでいました。
【公式】スタディサプリ|苦手克服・定期テスト対策~大学受験まで
無事にリリースできたので、このプロジェクトで変わったことや導入したソフトウェア、ツールについていくつかピックアップして書いていきたいと思います。
目次
- メンバーが増えた
- Infra as Code
- Deis
- AWS ECS + Docker + Locust による負荷テスト
- nginx (HTTP/2, ngx_mruby)
- 分析基盤
- 技術的課題
メンバーが増えた
前回の記事を書いた時はインフラ関連のエンジニア(Quipper では Engineering チームといいます)は私1人だったのですが、kamatama41 さん、lamanotrama さんが加わり、今は3人でちゃんとしたチームになりました。
メンバーが増えたことで、今まで手がつけられなかったことが大分できるようになりました。
Infra as Code
今回は AWS の環境から全て新規に構築するということで、Infra as Code 全開でやってみました。
- Terraform
- Roadworker
- Miam
- Ansible
- Ansible Tower
- ServerSpec
- Infrataster
Terraform と Roadworker/Miaml で AWS のリソースを定義し、Ansible でサーバーを Provisioning するという至ってオーソドックスな構成です。 全てのツールは CircleCI 上でテストから適用までできるようになっています。(Ansible に関しては、CircleCI から Ansible Tower の API を叩いて実行という構成になっています)
Playbook のテストは CircleCI 上で Docker で素の Ubuntu を起動し、そこに Playbook を適用し、ServerSpec, InfraTester でテストしています。 実際にやってみて、色々と気を付けなければいけない点はあり、初期はスピードが出なかったのですが、インフラの設計図が全てコードになっていて、暗黙知がなくなり、開発後半はスピードも安定性も出すことができたと思っています。
今後は、ここで得た知見を、今度はグローバルのプラットフォームにバックポートしていく予定です。
Deis
Deis は Docker/CoreOS/Fleet/Etcd/Golang/Python で構築された Private PaaS を実現するソフトウェアです。Deis の導入は今回のプロジェクトで一番難しかったことの1つでしょう。なにしろ、日本語はもちろん、英語でもプロダクションでどのように運用しているかという情報がなかったからです。公式からも AWS CloudFormation のテンプレートが提供されているのですが、正直あのままでは不安定すぎてプロダクションに投入できません。これについては長くなるので、別途 Qiita に書いてみたので、ご参照ください。日本でプロダクションに投入したのは初のはず。
Deis を AWS でプロダクションに投入するための Tips - Qiita
色々と大変ではあるのですが、半年以上検証した結果それなりに安定運用できています。 Deis の良い点は、とにかく Heroku Buildpack と互換性があるということです。
今回のスタディサプリのアプリケーションについてもコードは、海外で展開している Quipper School と同じコードを利用しています。そして、海外では Heroku でアプリケーションをホストして、並行して開発が進んでいます。 Deis は Heroku Buildpack と互換性があるため、デプロイの仕組みを別々に作らなくてもよく、git の push 先を Deis に切り替えるだけで、Heroku で動いしていたコードがそのまま動きます。
Heroku を使っているユーザは、行くのも戻るのも簡単なので移行の有力な選択肢になるのではないかと思います。ただし、それなりに手はかかるので、インフラにあまり手をかけられないという人は、Heroku Private Spaces も併せて検討することを忘れずに。
AWS ECS + Docker + Locust による負荷テスト
GKE + Docker + Locust による負荷テストを実施していましたが、今回、ネットワーク的に近いほうが負荷テストをし易いだろうということで、AWS ECS を利用して同じものを作ってみました。
https://github.com/hakobera/docker-locust-gke (これは GKE 版)
使い勝手はほぼ変わりませんが、ECS は利用する場合は幾つかメリットがあります。
- Docker Compose 互換の設定ファイルが使えるので、ローカルで構成をテストしてからそのまま持っていける
- Spot インスタンスが使えるので安い
ということで、負荷テストにお悩みの方は ECS + Dokcer + Locust も試してみると良いのではないでしょうか。 ECS版はソースを整理したら、公開したいと思います。とりあえず、Dockerfile だけ。Alpine はイメージサイズが小さくていいです。
FROM python:2.7-alpine
RUN apk -U add ca-certificates python-dev build-base && \
pip install locustio pyzmq && \
apk del python-dev && \
rm -r /var/cache/apk/* && \
mkdir /locust
WORKDIR /locust
COPY locustfile.py /locust/locustfile.py
RUN test -f requirements.txt && pip install -r requirements.txt; exit 0
EXPOSE 8089 5557 5558
ENTRYPOINT [ "/usr/local/bin/locust" ]
nginx (HTTP/2, ngx_mruby)
HTTP/2
https://studysapuri.jp/ にアクセスしてもらえればわかると思いますが、リバースプロキシは nginx かつ、プロトコルは HTTP/2 を利用しています。 HTTP/2 の恩恵で、画像がたくさんあるページなのですが、快適に表示することができていると思います。
今回、静的サイトに関してはアクセスされるのがほぼ日本のみということで、CDN をほぼ利用していませんが、HTTP/2 に対応していない CloudFront を利用するよりも配信が速かったです。
ngx_mruby
時代はプログラマブルなリバースプロキシだ、ということで、nginx 単体では難しい処理を ngx_mruby を利用して実装しています。具体的には、
- DoS 対策
- メンテナンス画面への切り替え処理
- TCP プロキシの backend サーバの動的 DNS Lookup (DNS resolve 機能、nginx+ にはあるけど、OSS にはないのです)
などです。nginx で上記のことができるようになったので、アプリケーション側で考慮することが減って実装や変更が楽になりました。
分析基盤
- fluentd
- embulk
- Kinesis + Lambda
- TreasureData
Quipper は BigQuery を利用していますが、今回のスタディサプリはリクルートマーケティングパートナーズとの合同プロジェクトでもあるので、彼らの分析基盤である TreasureData へデータ集約を行っています。fluentd で nginx のログを、embulk でマスタデータを、Kinesis + Lambda で Deis からのイベントデータを送信しています。
Kinesis + Lambda によるイベントデータ送信はあまり話を聞かないのですが、かなり便利なのでオススメです。fluentd の再送機能も良いのですが、障害対策のためにバッファをどれくらい取るかなどの設計が悩ましいですが、Kinesis + Lambda の組み合わせなら なら最大7日間イベントを保持、再送処理をしてくれるので、その辺をまるっと AWS にお任せできるので大変助かっています。サーバーレス万歳ですね。
https://github.com/hakobera/lambda-kinesis-bigquery
内部では上記の TreasureData 版を作って使っています。
技術的課題
モニタリングと通知をもっと効率的に
Quipper ではモニタリングに各種ツールを利用しており、
- Sentry
- Pingdog
- NewRelic
- Datadog
それぞれ便利なのですが、いくつか問題があります。リリースへ向けて、新規構築に重点を置いていたため、これからは監視、運用をどう効率化していくが解決するべき課題となっています。
- 見る場所が分散して、全体の状況を把握するするのが難しくなっている
- 一応、Datadog に集約して、Slack 通知という方針をとっているが、Integration がなくて集約しきれないものもあり悩み中
- アラートが来すぎる
- 領域がかぶっている監視が同時にアラートをあげて、重複して通知がくる
- 純粋にアラートが多すぎて、本当に重要なエラーを見逃しがち
Workflow エンジンを Luigi から自作の Ruby のやつに置き換える
Workflow エンジンについては引き続き、課題として認識中です。 Luigi 自体は素晴らしく、運用上も大きな問題はないのですが、
- Model が Ruby で書いてあるので、Ruby で書かれた Workflow エンジンがあると、そのコードが利用できて便利
- Python だとバッチ系のコードのメンテができる人が限られてしまう(どちらかというとこちらの方が問題)
という理由により、Ruby で書かれた Workflow エンジンを実装中です。 どんな感じになるのか興味がある方は、以下の連載記事をご覧ください。
http://qiita.com/hakobera/items/d7742cc0801a9c62ef72
そろそろ4回目書きます。 4回目書きました
Workflow Engine をつくろう! Part 4(Task の並列実行) - Qiita
負荷試験を CI に組み込む
ECS + Docker + Locust で負荷試験が簡単にできるようになったので、これを CI に組み込むことで定期的にパフォーマンスをチェックできるようになるといいなと思っていますが、まだできていません。
Ubuntu 16.04 LTS への乗り換え
upstart から systemd への変更が・・・ということでいつやるか悩み中。 Ansible が吸収してくれるようになったらかなとは思っている。
絶賛採用中です
Quipper ではここに書いてあるようなクラウドを積極的に活用したお仕事、技術的課題の解決に興味があるエンジニアを絶賛大募集しております。興味のある方は、以下の募集ページからご応募ください。ちなみに採用関係なく、情報交換もしていきたいので、もっと詳しく聞いてみたいという方は Twitter で @hakobera, @kamatama_41, @lamanotrama にメンション or DM をお気軽にどうぞ。
Quipper の DevOps のお仕事と技術的課題
技術的課題を書くと、それを解決してくれるエンジニアが採用できるって話は本当ですか?というのは冗談としても、今の技術的課題をブログにまとめて公開するノーガード戦法も良いかと思う。
— Kazuyuki Honda (@hakobera) May 25, 2015このツイートがそれなりに反応があったので、有言実行してみる。
最初に書いておくと、これはQuipperの採用のための記事です。Quipper では下記のようなお仕事、技術的課題の解決に興味がある DevOps エンジニアを絶賛大募集しております。興味のある方は、Wantedlyの募集ページ から「話を聞きに行きたい」をクリックしてみてください。応募までは行かないけど、もっと詳しい聞いてみたいという方は私個人にでも良いのでご連絡ください。(Twitter で @hakobera にメンション or DM、または hakoberaアットgmail.com までメールください)
2015年6月時点での技術的課題一覧
- Heroku から AWS への移行
- Elastic Beanstalk で運用しているアプリの Docker 化
- Infra As Code のより一層の推進
- BigQuery を利用したレポート基盤の構築
- OSS 業務
合わせて使いそうな技術一覧
- AWS 全般
- Docker
- BigQuery
- Nginx
- Hashicorp 製品全般(主に Terraform と Atlas)
- Ruby/Python/Go など(なんらかの言語でのプログラミングスキルは必要)
Heroku から AWS への移行
Quipper は開発環境も合わせると、200以上のアプリを Heroku で稼働させている Heroku のヘビーユーザです。特に Heroku Review Apps と同じような仕組みをかなり昔から運用していて、便利に使っています。詳細は以下のCTO のブログを参照。
非開発者もGitHub Flowに巻き込んでみんなハッピーになった話 - Masatomo Nakano Blog CircleCIでfeature branchをHerokuに継続deploy - Masatomo Nakano Blog
すごく便利に使っている Heroku ですが、以下の理由から一部のアプリケーションについては AWS への移行を検討しています。
- アクセスが増えてきて、2X Dyno でさばけなくなってきた。現状 PX (Performance) Dyno を利用しているが、$500/Dyno/Month と高く、コストパフォーマンスが結構悪い。
- サービスの主戦場が現時点ではアジア(フィリピン、インドネシア、タイ)であり、US リージョンしかない Heroku だとネットワーク的に遠く、レスポンスが気になる
- セキュリティが緩くなりがちである(詳細は書けないが、IPアドレスが固定できないので、制限が色々とかけにくい。固定IPをつける addon もあるが高い)
AWS に移行するにしても、現状の feature branch を簡単にプレビューできる環境は維持したいので、Docker を利用して以下の構成にする予定です。
- ステージング: Private PaaS の基盤として Flynn or Deis or Dokku Alternative を検討中
- 本番: [Elastic Beanstalk for Docker] で運用(http://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/create_deploy_docker.html)
なお、SPDY/HTTP2 を利用したいので、Elastic Beanstalk の前段に Nginx を置く予定(現状も、Heroku の前段に Nginx を置いている)
Elastic Beanstalk で運用しているアプリの Docker 化
Heroku の AWS 移行とも絡むのですが、現在 Elastic Beanstalk で運用している Worker アプリケーションを Docker 化するというのも課題の1つです。Elastic Beanstalk は大変便利ですが、2点ほど大きな問題を抱えています。
- ベースとなる AMI が Amazon Linux しか使えないので、ローカルでテスト環境を作りにくい
- .ebextension 配下に設定ファイルを置くことで、カスタマイズが可能なのだが、カオスになりやすく、Amazon Linux や Elastic Beanstalk のスタックのバージョンが上がると動かなくなることもある。ebextension の闇と呼んでいる。
後者は気合で乗りきれなくもないですが、前者は開発が相当やりにくくなっていたし、Quipper の他のサーバは Ubuntu なので、ここだけ OS が異なるのは管理上も面倒である。ということで、ここも Ubuntu で管理できるように Docker 化をしたいと考えている。
Infra As Code のより一層の推進
現在の Quipper の Infra As Code のレベルは、
- デプロイは全て CircleCI 経由で自動化
- Amazon VPC の一部は Terraform + CircleCI + Atlas によって自動化
- DNS は roadworker で CircleCI から自動適用
- Ansible によるサーバープロビジョニング
- 適用はまだ手動
- ServerSpec によるテストはまだ
- 一部の構成が CloudFormation のテンプレート化されている
今後もこの方向性は強く推進していきたい、アイデアとしては色々とあるし、ツールも進化していくの継続的に改善していきたい。
- ServerSpec によるインフラテストの追加
- CircleCI 経由で master ブランチの Ansible の適用の自動化
- Terraform の適用範囲の拡大
- CloudFormation テンプレートを Terraform で書き換え
- Docker イメージの自動ビルド
など。この分野はやることが無限にある感じなので、自動化大好きな方をお待ちしております。
BigQuery を利用したレポート基盤の構築
上記スライドの後半の事例で書いているように、データの投入は fluentd/embulk/mongobq などで解消済みであるが、スケージューリング、エラー時の再実行などの処理基盤がまだまだ弱い。現状、レポートの数がそれ程多くないので何とかなっているが、今後の業務拡大により回らなくなる可能性が高く、ココは早急に改善が必要だと考えている。
以前発表した BigQuery GAS 連携は1つの解にはなっているが、単純なレポートには良いが、中間テーブルを作成しながら集計していくような複雑なジョブの実行には向かない。これらに対する現在考えている解決策は以下だ。
- Job ネットの構築
- Luigi が良さそう
- Luigi の BigQuery Integration である Luigi-BigQuery を書いて、一部のレポートに適用済みで良い感じ
- スケジューラの改善
- 可視化 (Visualize)
- コストさえ許せば選択肢は色々とある。データサイエンティストの人と相談して決めていきたい。
- BigQuery コネクタのある製品:Mode Analytics, Bime, Chario, [Tableau(http://www.tableau.com/), QLikView など
- GAS で何とかするか、ゼロスクラッチで作るのも場合によってはあり
レポートの処理速度に関しては BigQuery が全てを解決してくれたので、スケジューラの構築、安定運用と可視化に取り組んでいきたい。
OSS 業務
これは課題ではないのですが、必要に応じて、OSS にコントリビュートする、OSS を書くというのも Quipper の DevOps の重要な仕事の1つなのであげておきます。書いたものを OSS として公開するのは、業務に支障がない限り、特に制限はありません。
現在使っているものも、使っていないものも含まれていますが、以下にこれまで Quipper の業務に関連する OSS をあげておきます。
業務のためにコントリビュートした OSS
- woothee/woothee · GitHub
- tagomoris/shib · GitHub
- abronte/BigQuery · GitHub
- kaizenplatform/fluent-plugin-bigquery · GitHub
- GoogleCloudPlatform/fluent-plugin-google-cloud · GitHub
- ixixi/fluent-plugin-sqs · GitHub
- y-ken/fluent-plugin-geoip · GitHub
業務のために書いた OSS
- hakobera/ebfly · GitHub
- hakobera/transfer · GitHub
- hakobera/mongobq · GitHub
- hakobera/fluent-plugin-heroku-syslog · GitHub
- hakobera/fluent-plugin-mixpanel · GitHub
- hakobera/embulk-output-gcs · GitHub
- hakobera/luigi-bigquery · GitHub
同僚のエンジニアが書いた最近の Quipper の状況を知ることができるブログ記事
Heroku アプリのログを fluentd で ElasticSearch に突っ込んで Kibana で監視する方法
目的
Kibana で Heroku アプリのログを可視化したい。ただし、レスポンスタイムとかは New Relic でも見れるので、ここではアプリが出力したらログを可視化する方法を紹介する。
また、今回、アプリからの出力を可能な限りに簡単にするために、アプリからは Heroku の STDOUT に出力するだけで、ログを Kibana サーバに送信できるようにしてみた。
具体的にはこう。(Ruby の場合) 出力の形式は、Treasure Data addon の方法 を真似ている。
puts "@[tag.name] #{{'uid'=>123}.to_json}"
これで、tag.name が fluentd の tag 名に、それに続く JSON 文字列が送信するデータとして処理される。
環境
- Amazon EC2 上に Kibana サーバを構築
- OS は Ubuntu 13.10
- td-agent と ElasticSearch は導入済み
タイトルで fluentd と書いたが、正確には td-agent を使っているので、fluentd を使っている人は適宜読み替えること。
ログデータの流れ
処理の概要は以下の通り。
Heroku -> (syslog drains) -> rsyslog -> (syslog file) -> Fluentd(in_tail, rewrite, parser, elasticsearch) -> ElasticSearch -> Kibana
- Heroku の syslog drains を利用して、Kibana サーバに syslog を送信
- Kibana サーバに rsyslog サーバを立てて、Heroku からの syslog を受信して、ファイルに出力
- Fluentd の in_tail 機能を利用して、ログを読み込み、rewrite, parser プラグインを利用して、ログの変形とフィルタリング
- elasticsearch プラグインを利用して ElasticSearch にログを投入
- Kibana で見る
Heroku の設定
Heroku の syslog drains 機能を利用して、syslog を指定したサーバに送信する設定をする。 Kibana サーバで 5140 ポートで rsyslog サーバを起動する場合。
$ heroku drains:add syslog://[kibana-server]:5140 -a [heroku-app-name] Successfully added syslog://[kibana-server]:5140
追加が完了したら、heroku drains コマンドで、drain ID を取得する。
この d. で始まる drain ID は後で使うので、記録しておく。
$ heroku drains -a [heroku-app-name] syslog://[kibana-server]:5140 (d.XXXX) # ~~~~~~~~ ここが drain ID
参考:https://devcenter.heroku.com/articles/logging#syslog-drains
注意点としては、Kibana サーバを EC2 に立てている場合は、Elastic IP を設定した上で、Public DNS をサーバ名として指定する必要があること。これは Heroku 側で AWS の Private Address として Look up できないといけない Heroku のセキュリティ上の仕様のため。
参考: https://devcenter.heroku.com/articles/logging#security-access この制限は今はない。
rsyslog の設定
TCP サーバの起動
Heroku は UDP ではなく TCP で syslog を送信してくるので、rsyslog で TCP サーバを起動する。
/etc/rsyslog.conf を開いて、以下を追記(または、今ある要素をコメントアウト解除)
$ModLoad imtcp $InputTCPServerRun 5140 # ポート番号は heroku drains で設定したポートを指定。
ファイル作成権限の変更
デフォルトだと、syslog は root:adm に 0640 で作成されるので、fluentd から読み出すことができない。なので、ファイルの作成権限の変更を行います。同じく、/etc/rsyslog.conf の最後に以下を追記する。
$FileCreateMode 0644 $DirCreateMode 0755
参考: http://y-ken.hatenablog.com/entry/fluentd-syslog-permission
ログファイルの振り分け
デフォルトだと、/var/log/syslog に heroku のログが出力されていまうのだが、これだと fluentd で in_tail しにくいので、これを別ファイルに振り分ける。ここでは /var/log/heroku に出力するようにしてみる。
/etc/rsyslog.d/40-heroku.conf という名前のファイルを作成し、以下の内容を記述。
if $hostname startswith '[heroku drain ID]' then /var/log/heroku & ~
1行目が振り分け設定。2行目が1行目で一致したログを後続の syslog に出力しないようにする設定。 もし、複数の Heroku の syslog を受ける場合は、上記の2行をdrain IDを変えながら、繰り返して記述する。
RuleSet を使って、TCP で受け付けるデータのフィルタリングとかすると良いかも。(ここは調整中) http://www.rsyslog.com/doc/multi_ruleset.html
ログローテーションの設定
振り分け設定したログに対して、/etc/logrotate.d/rsyslog にログローテーションの設定をする。以下は daily で 7日間でローテーションする設定する例。
/var/log/heroku
{
rotate 7
daily
missingok
notifempty
delaycompress
compress
postrotate
reload rsyslog >/dev/null 2>&1 || true
endscript
}
rsyslog を再起動
全ての設定を保存したら、rsyslog を再起動。
$ sudo service rsyslog restart
AWS security group の設定
AWS の security group の設定で、EC2 インスタンスに紐付いた security group の TCP 5140 ポートを開放する設定をする。Management Console からでも良いし、aws cli で以下のようにしても良い。
$ aws ec2 authorize-security-group-ingress --group-name MySecurityGroup --protocol tcp --port 5140 --cidr 0.0.0.0/32
AWSじゃない人は、Firewallの設定で同様に 5140 ポートを開放する。
正しく設定できれば、この時点で /var/log/heroku に heroku の syslog が出力されているはず。tailして確認してみる。
$ tail -f /var/log/heroku Feb 2 03:41:32 [drain ID] app[web.`] Started GET "/XXX" for XXX.XXX.XXX.XXX at 2014-02-02 03:41:32 +0000
こんな感じのログが見えれば、設定は完了。
fluentd の設定
必要な gem のインストール
td-agentの場合は、fluent-gem を使うように注意する。
$ fluent-gem install fluent-plugin-rewrite $ fluent-gem install fluent-plugin-parser $ fluent-gem install fluent-plugin-elasticsearch
td-agent.conf の設定
処理の概要は、以下の通り。
- in_tail で heroku の syslog を解析
- fluent-plugin-rewrite でアプリログと Heroku のログを振り分け
- fluent-plugin-parser でJSON データの解析
- fluent-plugin-elasticesearch で ElasticSearch に出力
実際の /etc/td-agent/td-agent.conf の設定はこう。
<source>
type tail
path /var/log/heroku
pos_file /var/log/td-agent/posfile_heroku.pos
format /^(?<time>[^ ]*\s+[^ ]*\s+[^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[a-zA-Z0-9\.]+)\])? *(?<message>.*)$/
time_format %b %d %H:%M:%S
tag heroku.syslog
</source>
# アプリログとHerokuが出力するログを振り分け
<match heroku.syslog>
type rewrite
<rule>
key message
pattern ^@\[([a-zA-Z0-9_\.]+)\]\s+.*$
append_to_tag true
fallback others
</rule>
<rule>
key message
pattern ^@\[[a-zA-Z0-9_\.]+\]\s+(.*)$
replace \1
</rule>
</match>
# アプリログ以外は読み捨て
<match heroku.syslog.others>
type null
</match>
# アプリログの処理
# ここでは @[app.XXX] JSON と出力していることを想定
# JSON データは message プロパティに文字列として格納されている
<match heroku.syslog.app.**>
type parser
remove_prefix heroku.syslog
key_name message
format json
reserve_data true
</match>
# ElasticSearch に出力
<match app.**>
type elasticsearch
type_name app
include_tag_key true
tag_key @log_name
host localhost
port 9200
logstash_format true
flush_interval 3s
</match>
再起動
設定を保存したら、fluentd (td-agent) を再起動。
$ sudo service td-agent restart
しばらくすると、Kibana でデータが見えるようになる。楽しい!
thunkify する時に注意すべきたった1つのこと
結論
thunkifyをオブジェクトのメソッドに適用する時は、元のメソッドに代入するか、thisを元のオブジェクトにbindすること。
fs.readFile = thunkify(fs.readFile) // または var readFile = thunkify(fs.readFile.bind(fs));
- ただし、
fs.readFileはvar readFile = thunkify(fs.readFile.bind(fs));でも動きます。詳細は以下。 - 元のオブジェクトに影響を与えない、ということを考えると後者の方が良いかも。
原因
thunkify は、Node で generator を使ったプログラムを書く時に便利ですが、1つ気をつけることがあります。
thunkify の実装は以下のようになっています。
function thunkify(fn){
return function(){
// 省略
fn.apply(this, args); // (1)
return function(fn){
// 省略
}
}
};
上記の (1) の部分のthisが曲者で、
var obj = {
func1: function (cb) {
console.log('func1');
this.func2(cb); // (2) 動かない!
},
func2: function (cb) {
console.log('func2');
cb(null, 'func2');
}
};
こういうオブジェクトに対して、
var func1 = thunkify(obj.func1);
とやってしまうと、(2) の部分のthisがglobalスコープになってしまって、TypeError: Object #<Object> has no method 'func2'と言われてしまうのです。
ただし、fs.readFileのように内部でthisを利用しないメソッドは動いてしまうので、なかなか気が付きにくい。自分で書いたメソッドの場合は良いけど、ライブラリを利用する場合は、念の為に元のメソッドに代入するか、thisを元のオブジェクトにbindしておいた方が良さそう。
気がついた経緯から解決まで
Twitter で高速解決。
@hakobera 中で apply してるのが this だからじゃないですかね?
— Jxck (@Jxck_) 2014, 1月 16@hakobera var some = thunkify(fs.readFile.bind(fs)); してやればいいのでは
— ミルモでポン! (@KOBA789) 2014, 1月 16Thanks, @Jack_ さん、@KOBA789 さん。
参考資料
とてもわかりやすいジェネレータの解説
ジェネレータの解説と非同期への適用 - Block Rockin’ Codes
おまけ: エラー再現コード
var thunkify = require('thunkify');
var obj = {
func1: function (cb) {
console.log('func1');
this.func2(cb); // (2) 動かない!
},
func2: function (cb) {
console.log('func2');
cb(null, 'func2');
}
};
var func1 = thunkify(obj.func1);
//var func1 = thunkify(obj.func1.bind(obj)); // こっちならOK
function* gen() {
yield func1();
};
var g = gen();
g.next();
ワンクリックで Chrome のスクリーンショットを Gyazo で共有できる Chrome Extension を作りました
インストール方法
Chrome ウェブストアで公開中です。
ソース
Github上で開発しています。問題報告やプルリクエストなど大歓迎です。
https://github.com/hakobera/gyazo-shot
開発動機および機能
開発中の画面とかをサクッと共有するのに、Gyazoはとても便利です。 ただし、Web開発では、圧倒的にブラウザの表示内容を共有することが多く、いちいち領域選択して行くのは面倒です。また、領域選択に失敗して綺麗に撮れない場合もあります。
Gyazo Shot で目指したのは、「簡単にWebブラウザのスクリーンショットを共有できる」です。 Gyazo Shot はワンクリックで表示しているタブの表示領域のスクリーンショットを Gyazo で共有することができます。本家のクライアントアプリと同様、共有後は共有ページがブラウザで開き、クリップボードにURLがコピーされているので、すぐに確認して、BugTrackerやチャットなどで共有することができます。

プライベート Gyazo サーバにも対応
仕事などセキュリティ上の理由で、プライベート Gyazo サーバを使っている人も多いと思います。Gyazo Shot では設定画面でサーバのURLを変更できるので、こうした用途にも対応できます。
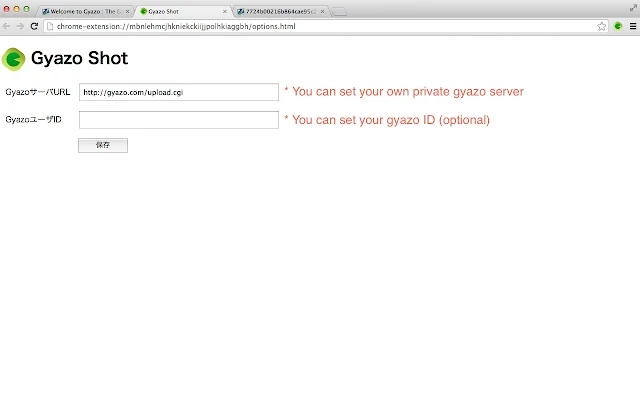
ユーザIDも指定できる
基本的にはユーザID無しで利用できるけど、消したい、とか、一覧を見たいとかある場合は、本家の Gyazo アプリをインストールして、一度使うと、以下のコマンドで取り出せるので、設定画面で設定してください。
cat ~/Library/Gyazo/id
ただし、Mac OS限定。WindowsとLinuxは後で調べます。
Gyazo Gif は?
APIの仕様が公開されていない(と思う)ので、対応していません。
作ってみた感想
年末で少しだけ時間ができたので、カッとなってやった。半日くらいで、思っていたより簡単にできた。特に、JavaScript で簡単にバイナリデータ(TypedArray, Blob, FormDataなど)が扱えるようなっていて、ちょっと感動した。興味がある人は background.js あたりを見ると良いと思う。
https://github.com/hakobera/gyazo-shot/blob/master/crx/scripts/background.js